Goal
In part 1 we discussed the general structure of the static website.For me it was important to keep the content creation and the website operations seperate.
I want to edit my website locally, work on it locally and then just publish everything with a push to the repository. First, I synced the website manually to my server to publish it. That’s fine for testing, but for working on it I wanted something more robust: a CI/CD pipeline.
Once this is setup I can concentrate on the content instead of working the operations all everytime I want to change something.
Setting up the CI/CD pipeline
Overview
This is the general overview of how the system works:
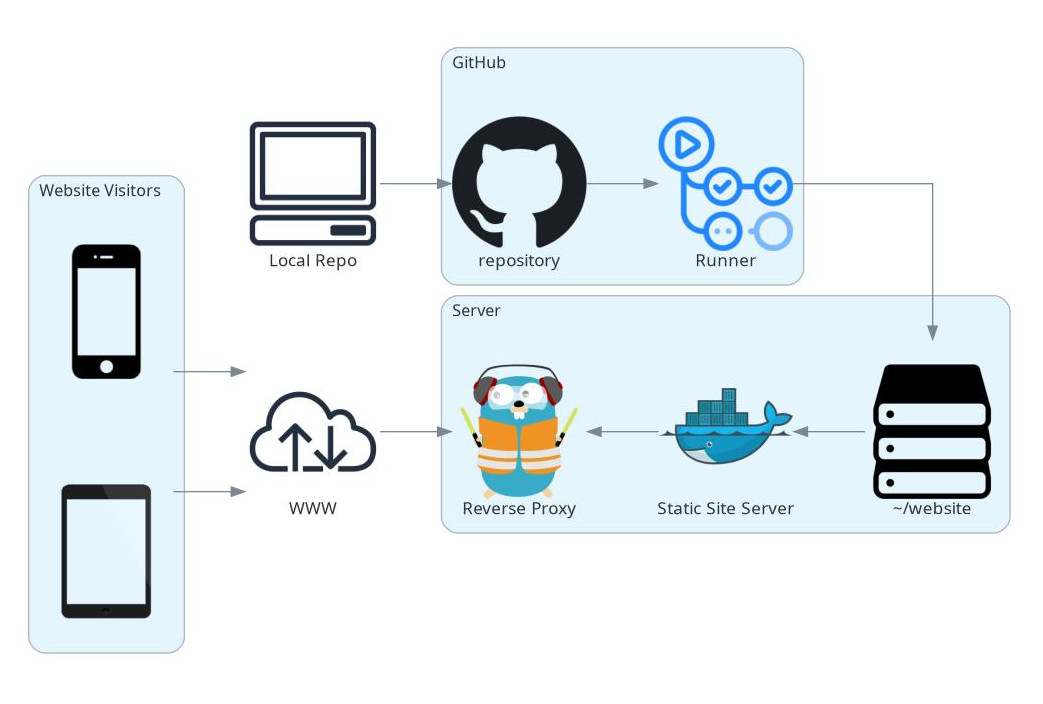
I have GitHub repository with the content of my website inside of it. Everytime I push a change to this resository it deploys the changes to my server. The files themselves are stored in the filesystem.
The hugo server runs inside of a docker container. This isn’t ideal from what I have read somewhere but it allows me to have it behind traefik, a modern and easy to use reverse proxy. The nice thing about traefik is that it automatically picks up new containers and you don’t have to worry about many things.
Deploying Markdown Files
There are many ways to deploy a set of markdown files to a remote server. I choose rsync which stands for remote sync. It tries to minimize the amount of data that needs to be transfered although I am not sure if that’s still true
if you run it inside a GitHub Actions runner. Anyway, a couple of markdown files aren’t too big, so I don’t worry too much about it.
Getting started with GitHub Actions
GitHub Actions aren’t too complicated if you have used other CI/CD systems before. They are configured with YAML files inside a .github/workflows/ directory inside your repository. You can find the
full documentation here.
Each workflow has a trigger and a set of jobs. The trigger determines when the workflow is run. Here, it happens for every push on main. You could have different workflows for different branches e.g., when you want to deploy to a test
environment first. That’s not what I do because there is no need. I just deploy to the live website. The chance that something breaks is minimal.
The job key in the YAML describes what the runner is supposed to do. Once it works it’s fine but debugging is a real pain because you need to push everytime and see what happens. I wish there was a better way to do that, but I haven’t found a one.
The job here has 4 steps:
- Checkout the repository and its submodules
- Install the SSH key to sync files to the remote server
- Sync the files with
rsync - Clean up the SSH related files
Point 4 is probably not necessary but you never know what’s happening with a runner after you used it and you don’t want to leak your private SSH key.
Managing Secrets
rsync is build on top of SSH. Therefore, I need a private key and a username to connect to the server. It’s bad practice to hardcode these into the repository. My secrets are managed by GitHub and can be used inside a runner by
secrets.<YOUR SECRET> where <YOUR SECRET> is the name you have given the secret in the settings. For more information on how to setup your own secrets checkout the docs
Bringing everything together
We now got all the parts to bring everything together. The following script is saved as .github/workflows/main.yml and runs every time something is pushed to main.
on:
push:
branches:
- main
workflow_dispatch:
jobs:
deploy:
name: deploy
runs-on: ubuntu-latest
steps:
- name: checkout repo
uses: actions/checkout@v3
with:
submodules: 'true'
- name: install ssh keys
# check this thread to understand why its needed:
# https://stackoverflow.com/a/70447517
run: |
install -m 600 -D /dev/null ~/.ssh/id_rsa
echo "${{ secrets.SSH_PRIVATE_KEY }}" > ~/.ssh/id_rsa
ssh-keyscan -H ${{ secrets.SSH_HOST }} > ~/.ssh/known_hosts
- name: deploy to remote
run: rsync -rav --delete --exclude={'.git','.github','.gitmodules','hugo'} . ${{ secrets.SSH_USER }}@${{ secrets.SSH_HOST }}:/home/${{ secrets.SSH_USER }}/website
- name: clean up
run: rm -rf ~/.ssh
I am sure there are other ways to do the job, but that’s what I came up with. I think it’s reasonable for now and unless I run into problems I will likely keep it that way.
Closing Thoughts
The whole thing took about a day of work from starting with Hugo to having the deployment setup ready.
The things I spent most time on:
- selecting a themselves
- deciding which way I wanted to deploy the Website
That’s all there is to this website. I tried to keep it simple and I think I succeeded in that.
I am open to do contracting as a backend software and data engineer. I like to automate processes. I like technical writing. Check out how we can work together.